
#3 Логарифмическая борьба с тех. долгом
Еще одна не строгоформализованная техника борьбы с тех. долгом - логарифмический подход. Суть простая: вы просто выделяете 1-n человек в команде, которые заступают на “баг”-дежурство. Но как и во всем остальном в этом подходе так же имеется хитрость. Суть их работы сводится к 2м режимам: авральный и нормальный.
Авральный - это когда все пропало и ваш сервис крайне в плачевном состоянии - тут не до разговоров, ищем, чиним, стучим в барабан и все в таком духе. Собственно нечего рассказывать, все и так понятно.
Нормальный - тут уже интереснее. Допустим, у вас нет багов в проде, тогда силы этого человека тратятся на закрытие тех. долга, не обязательно архитектурного, эту работу можно сделать на усмотрение разработчика, если он в состоянии не борзеть в край и не переписывать ядро системы на горутины. У вас не было автотестов, был корявый архитектурный долг, не было единого стиля логирования - вот он ваш шанс наверстать упущенное.
А что делать, если баги есть?
Схем простая, коэффициенты можно варьировать - но суть останется та же.
1. Берем баг, если фиксим за 30 минут -> котим в прод + хотфикс в dev(нюансы могут отличаться от вашего flow), если не решаем - повышаем сложность до minor и пишем в тикет (или что там у вас) все что смогли накопать за 30 минут
2. Если вам попался баг minor то пытаемся зафорсить его за 1 час и все как в пункте один. На выходе либо фикс либо major с оценкой 2 часа.
3. Critical -> 4ч; Если выше - ну тут уже нужно задумываться, а нужно ли этот баг фиксить или воркэрануд подойдет и все такое в этом духе.
Какие могут быть альтернативные занятия?
1. Если багов нет -> то их нужно искать. Где? Например в логах, зачем пишем их пачками, если не анализируем-то?
2. Если багов слишком много, то можно поделить дневное время на 2 части -> 1/2 фиксим + 1/2 импрувим
3. Любые вариации, которые вы найдете полезными
Еще одна не строгоформализованная техника борьбы с тех. долгом - логарифмический подход. Суть простая: вы просто выделяете 1-n человек в команде, которые заступают на “баг”-дежурство. Но как и во всем остальном в этом подходе так же имеется хитрость. Суть их работы сводится к 2м режимам: авральный и нормальный.
Авральный - это когда все пропало и ваш сервис крайне в плачевном состоянии - тут не до разговоров, ищем, чиним, стучим в барабан и все в таком духе. Собственно нечего рассказывать, все и так понятно.
Нормальный - тут уже интереснее. Допустим, у вас нет багов в проде, тогда силы этого человека тратятся на закрытие тех. долга, не обязательно архитектурного, эту работу можно сделать на усмотрение разработчика, если он в состоянии не борзеть в край и не переписывать ядро системы на горутины. У вас не было автотестов, был корявый архитектурный долг, не было единого стиля логирования - вот он ваш шанс наверстать упущенное.
А что делать, если баги есть?
Схем простая, коэффициенты можно варьировать - но суть останется та же.
1. Берем баг, если фиксим за 30 минут -> котим в прод + хотфикс в dev(нюансы могут отличаться от вашего flow), если не решаем - повышаем сложность до minor и пишем в тикет (или что там у вас) все что смогли накопать за 30 минут
2. Если вам попался баг minor то пытаемся зафорсить его за 1 час и все как в пункте один. На выходе либо фикс либо major с оценкой 2 часа.
3. Critical -> 4ч; Если выше - ну тут уже нужно задумываться, а нужно ли этот баг фиксить или воркэрануд подойдет и все такое в этом духе.
Какие могут быть альтернативные занятия?
1. Если багов нет -> то их нужно искать. Где? Например в логах, зачем пишем их пачками, если не анализируем-то?
2. Если багов слишком много, то можно поделить дневное время на 2 части -> 1/2 фиксим + 1/2 импрувим
3. Любые вариации, которые вы найдете полезными
#4 DevOps != CI + CD
Я долго собирался с мыслями, чтобы написать на тему от которой меня больше всего бомбит. DevOps - это не про автоматизацию, и DevOps - это, блин, не инженер. Это всего-то история о том, что разработка, тестирование, поставка и эксплуатация - это один большой, но тем не менее общий процесс - командная работа направленная на обеспечение качества продукта. Идея была не в том, чтобы автоматизировать все подряд, а в том, чтобы сделать все прозрачно для всех, чтобы голова от того, что продукт хреновый болела не у пользователей, а у команды.
Да, безусловно, есть ряд практик, которые помогают сделать этот процесс понятнее, прозрачнее, лучше и быстрее, но они в разных реализациях могут очень даже противоречить друг другу. Например современные тенденции говорят, что пофиг сколько ваш продукт падает за день (при одном доп. условии, но об этом потом). Тем не менее в головах людей устоялась мысль о том, что это про автоматизацию.
Вывернем все на изнанку: допустим у вас Infrastructure as Code, CI & CD as Code, monitoring as code и вообще все as Code и 100% автоматизация, и если вы, как разработчик, не знаете свою поддержку, как устроен мониторинг - то у вас не DevOps, у вас хорошо поставленное перекидывание ответственности через забор, просто забор автоматизированный.
З.Ы.
След. несколько дней буду писать про тьму тьмущую идей, которые породились в погоне за devopsхайпом
Я долго собирался с мыслями, чтобы написать на тему от которой меня больше всего бомбит. DevOps - это не про автоматизацию, и DevOps - это, блин, не инженер. Это всего-то история о том, что разработка, тестирование, поставка и эксплуатация - это один большой, но тем не менее общий процесс - командная работа направленная на обеспечение качества продукта. Идея была не в том, чтобы автоматизировать все подряд, а в том, чтобы сделать все прозрачно для всех, чтобы голова от того, что продукт хреновый болела не у пользователей, а у команды.
Да, безусловно, есть ряд практик, которые помогают сделать этот процесс понятнее, прозрачнее, лучше и быстрее, но они в разных реализациях могут очень даже противоречить друг другу. Например современные тенденции говорят, что пофиг сколько ваш продукт падает за день (при одном доп. условии, но об этом потом). Тем не менее в головах людей устоялась мысль о том, что это про автоматизацию.
Вывернем все на изнанку: допустим у вас Infrastructure as Code, CI & CD as Code, monitoring as code и вообще все as Code и 100% автоматизация, и если вы, как разработчик, не знаете свою поддержку, как устроен мониторинг - то у вас не DevOps, у вас хорошо поставленное перекидывание ответственности через забор, просто забор автоматизированный.
З.Ы.
След. несколько дней буду писать про тьму тьмущую идей, которые породились в погоне за devopsхайпом
Как продают CI и CD в вашу компанию?
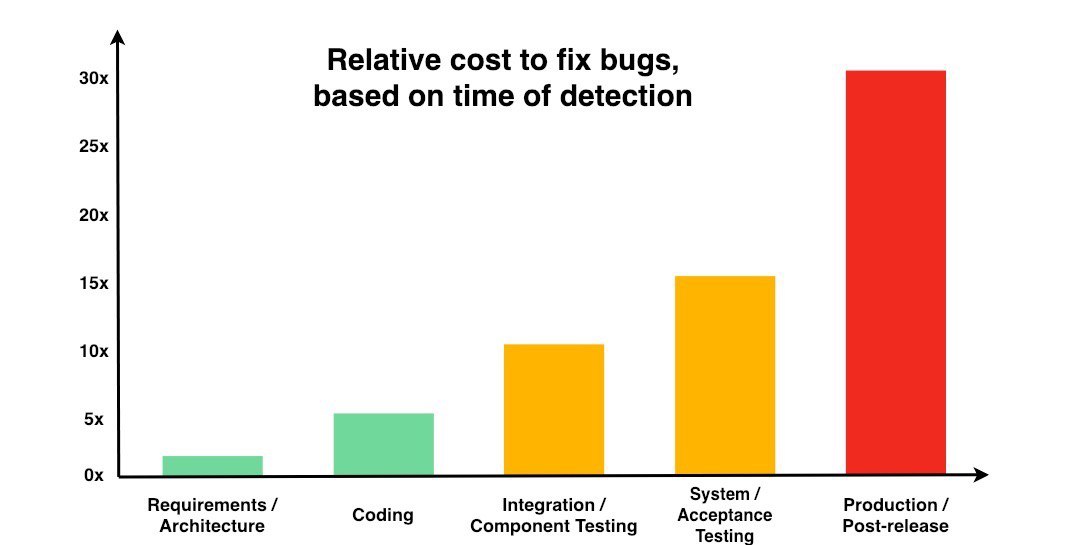
Думаю мало для кого секрет, что стоимость исправления бага в коде экспоненциально зависит от этапа обнаружения, фикс бага на этапе анализа требований ровным счетом не стоит вам ничего, а бага в продакшн может обойтись в приличную сумму. Не уверен, что есть состоятельные исследования на эту тему, зато есть укоренелое расхожее мнение.
Есть два варианта втюхивать практики: зажечь команду красивыми идеями, картинками и убедительными обоснованиями или впарить топ-менеджменту красивые перспективы сулящие в том числе горы денег. Первое обычно выливается в карго-культ, второе - в обмазку вендором/консультантом.
1. И так, ваш аргумент номер один: ошибка со временем дорожает - нужно научиться находить эти ошибки быстрее. Вы конечно можете нанять толпу аналитиков, но они не спасут вас от плохой программной реализации, вы можете сделать каждый шаг процесса перепроверяемым и все в таком духе - это сомнительно повышает качество и существенно затягивает время разработки. Continuous Integration... шепчет консультант, бездумные железки стоят копейки и они допускают ошибки куда реже человеков.
2. T2M - мифическая метрика, которой все грезят и мало кто может посчитать выгоду. Незаделиверенный продукт не приносит денег. Нельзя продать фичу, которой нет в проде (на самом деле можно). Все вокруг стремятся обогнать конкурента и делают это безумно неправильно - нанимают много новых людей, потом координаторов для этих людей, потом нанимают целые процессные отделы, которые будут придумывать как им эту работу работать и как собирать метрики о качестве этой работы. Потом команды нанимают псевдоразработчиков, которые будут подделывать метрики и т.д. - эдакая гонка вооружений и конфронтаций. А что делает Амазон, когда приходит вам продавать свой CI/CD? Оч просто, они показывают одну картинку и обрамляют ее сочным рассказом:
Когда-то в компании мы посчитали метрику Time2Market -> и она получилась в среднем 3,5 месяца на фичу. Мы начали анализировать процесс и с ужасом обнаружили, что за эти 3,5 месяца разработка занимала примерно 15 дней, тестирование 1 день, и установка в прод 2 часа - остальное время продукт просто лежал: ждал пока его скомпилируют, запустят автотесты, соберут поставку, установят на тестовый стенд, потом на другой тестовый стенд, потом соберут новую поставку и в конечном итоге установят на прод. По этому в отличии от того, чтобы концентрировать свое внимание на ускорении “написания/сборки/тестирования/деплоя” кода - мы сосредоточились на устранении времени простоя. Мы не говорим, что улучшением вещей выше не нужно заниматься, просто на ранних этапах они принесут вам куда меньше прибыли. Сокращение времени разработки вдвое принесет вам всего -5% T2M, в то время как сокращённый вдвое простой -45%.
Естественно вам никто не говорит про сайды эффекты, но, согласитесь, продажа красивая и про высокие и красивые материи.
Думаю мало для кого секрет, что стоимость исправления бага в коде экспоненциально зависит от этапа обнаружения, фикс бага на этапе анализа требований ровным счетом не стоит вам ничего, а бага в продакшн может обойтись в приличную сумму. Не уверен, что есть состоятельные исследования на эту тему, зато есть укоренелое расхожее мнение.
Есть два варианта втюхивать практики: зажечь команду красивыми идеями, картинками и убедительными обоснованиями или впарить топ-менеджменту красивые перспективы сулящие в том числе горы денег. Первое обычно выливается в карго-культ, второе - в обмазку вендором/консультантом.
1. И так, ваш аргумент номер один: ошибка со временем дорожает - нужно научиться находить эти ошибки быстрее. Вы конечно можете нанять толпу аналитиков, но они не спасут вас от плохой программной реализации, вы можете сделать каждый шаг процесса перепроверяемым и все в таком духе - это сомнительно повышает качество и существенно затягивает время разработки. Continuous Integration... шепчет консультант, бездумные железки стоят копейки и они допускают ошибки куда реже человеков.
2. T2M - мифическая метрика, которой все грезят и мало кто может посчитать выгоду. Незаделиверенный продукт не приносит денег. Нельзя продать фичу, которой нет в проде (на самом деле можно). Все вокруг стремятся обогнать конкурента и делают это безумно неправильно - нанимают много новых людей, потом координаторов для этих людей, потом нанимают целые процессные отделы, которые будут придумывать как им эту работу работать и как собирать метрики о качестве этой работы. Потом команды нанимают псевдоразработчиков, которые будут подделывать метрики и т.д. - эдакая гонка вооружений и конфронтаций. А что делает Амазон, когда приходит вам продавать свой CI/CD? Оч просто, они показывают одну картинку и обрамляют ее сочным рассказом:
Когда-то в компании мы посчитали метрику Time2Market -> и она получилась в среднем 3,5 месяца на фичу. Мы начали анализировать процесс и с ужасом обнаружили, что за эти 3,5 месяца разработка занимала примерно 15 дней, тестирование 1 день, и установка в прод 2 часа - остальное время продукт просто лежал: ждал пока его скомпилируют, запустят автотесты, соберут поставку, установят на тестовый стенд, потом на другой тестовый стенд, потом соберут новую поставку и в конечном итоге установят на прод. По этому в отличии от того, чтобы концентрировать свое внимание на ускорении “написания/сборки/тестирования/деплоя” кода - мы сосредоточились на устранении времени простоя. Мы не говорим, что улучшением вещей выше не нужно заниматься, просто на ранних этапах они принесут вам куда меньше прибыли. Сокращение времени разработки вдвое принесет вам всего -5% T2M, в то время как сокращённый вдвое простой -45%.
Естественно вам никто не говорит про сайды эффекты, но, согласитесь, продажа красивая и про высокие и красивые материи.
{kind=link}
DORA State of DevOps
Если вы любите рассказвыать о том, что DevOps спасет мир -> то я настоятельно рекомендую читать отчеты DevOps Research and Assessment - там не глупые люди говорят о том, куда все это дело движется в западном мире. Для сравнения приведу отчет 2019 и основные тренды/смещения акцентов.
И если тренды с аджайлом, продуктовым подходом, уходом в облака и использованием опенсорс+микросервисы - в целом ни у кого не вызывают вопросов. То под сомнение уже можно поставить стандартизацию и при этом уход от централизованного подхода.
Штуки которые в энтерпрайзе были практически несломные - это контроль и управление сверху vs доверие и измерение метрик. А вот то, что порвет крышечку не одному менеджеру это тренд Mean Time Between Failures (MTBF) -> Mean Time To Repair (MTTR).
У кого-то хватило яиц подменить слово стабильность и надежность фордовским вариантом поддержки, да и какая разница, сколько там ваших процентов микросервисов лежит, если вы умеете их подменять на лету меньше чем за секунду?
Если вы любите рассказвыать о том, что DevOps спасет мир -> то я настоятельно рекомендую читать отчеты DevOps Research and Assessment - там не глупые люди говорят о том, куда все это дело движется в западном мире. Для сравнения приведу отчет 2019 и основные тренды/смещения акцентов.
И если тренды с аджайлом, продуктовым подходом, уходом в облака и использованием опенсорс+микросервисы - в целом ни у кого не вызывают вопросов. То под сомнение уже можно поставить стандартизацию и при этом уход от централизованного подхода.
Штуки которые в энтерпрайзе были практически несломные - это контроль и управление сверху vs доверие и измерение метрик. А вот то, что порвет крышечку не одному менеджеру это тренд Mean Time Between Failures (MTBF) -> Mean Time To Repair (MTTR).
У кого-то хватило яиц подменить слово стабильность и надежность фордовским вариантом поддержки, да и какая разница, сколько там ваших процентов микросервисов лежит, если вы умеете их подменять на лету меньше чем за секунду?
{kind=link}
Иногда можно пустить все на самотек
В пятницу закончился интенсив длинной в 2 месяца. За это время мы со старой командой должны были доказать, что можно создать тот же продукт на базе распределенной архитектуры, попутно избавиться от зависимостей eclipse, swt, awt и другого добра, которого внутри хватало.
Все 2 месяца я честно пытался поднимать те проблемы, которые есть внутри, и мы честно их обсуждали, я говорил, что лучше потратить 4 лишних часа на то, чтобы понять, чем делать дела вразнобой. Удивительно, но за это время люди внутри научились приходить к консенсусу по любому вопросу за 15 минут.
Формальных причин для того, чтобы не успеть сделать PoC не было, т.к. нужно было просто собрать все части воедино. По этому части людей, с которыми раньше мы честно сидели и декомпозировали задачи я сказал: в этот раз без меня, цель спринта понятна, задачи мы декомпозировали 100 раз, вы справитесь.
Потом так случайно произошло, что я опоздал на первые 40 минут планирования, когда пришел все было почти готово и мне оставалось задать всего 2 вопроса:
- всем ли понятно, что именно нужно сделать в каждой из этих задач?
- сделав эти задачи, достигнем ли мы конечную цель спринта?
Получив утвердительный ответ, я пошел 2 недели заниматься своими делами. Потому что лучше накосячить внутри компании, чем прилюдно на конференции через пол года.
В пятницу закончился интенсив длинной в 2 месяца. За это время мы со старой командой должны были доказать, что можно создать тот же продукт на базе распределенной архитектуры, попутно избавиться от зависимостей eclipse, swt, awt и другого добра, которого внутри хватало.
Все 2 месяца я честно пытался поднимать те проблемы, которые есть внутри, и мы честно их обсуждали, я говорил, что лучше потратить 4 лишних часа на то, чтобы понять, чем делать дела вразнобой. Удивительно, но за это время люди внутри научились приходить к консенсусу по любому вопросу за 15 минут.
Формальных причин для того, чтобы не успеть сделать PoC не было, т.к. нужно было просто собрать все части воедино. По этому части людей, с которыми раньше мы честно сидели и декомпозировали задачи я сказал: в этот раз без меня, цель спринта понятна, задачи мы декомпозировали 100 раз, вы справитесь.
Потом так случайно произошло, что я опоздал на первые 40 минут планирования, когда пришел все было почти готово и мне оставалось задать всего 2 вопроса:
- всем ли понятно, что именно нужно сделать в каждой из этих задач?
- сделав эти задачи, достигнем ли мы конечную цель спринта?
Получив утвердительный ответ, я пошел 2 недели заниматься своими делами. Потому что лучше накосячить внутри компании, чем прилюдно на конференции через пол года.
О том, как я в очередной раз положил прод
Большую часть подобных оплошностей я допускал, как и принято в нормальных кругах, хотфиксами. Ну так бывает, когда сервису плохо, то малоинвазивный фикс, который катится без автотестов и из локальный сборки валит все к херам. Или когда в последнюю секунду загоняешь в состав релиза хотелку бигбоса.
Но в тот раз все было по совести. Кровавый финтех энтерпрайз ставит высокие заборы между тестированием, разработкой, поддержкой приложения и поддержкой инфраструктуры. Зачем это делается? Ну чтоб вы не вошли в преступный сговор и не украли ценные данные (по крайней мере так нам говорили). На практике это скатывается в общение через тикет системы с прикладыванием подорожника и надеждой что инфраструктурные изменения (как и любые другие) будут сделаны по совести.
И так, у нас было 5 тестовых стендов разной степени осознанности, сначала в докерах на заглушках, потом на тестовый стенд, потом staging, preprod -> prod. С автотестами и ручными и демо бизнесу и еще много чем. Котим в прод и все валится к херам.
Смотрим ошибку - приложение не поднимается из-за циклических зависимостей. Ну да, так-то серьезный косяк. А локально и на тестовых стендах все работает. А в проде не работает. Оказалось что всему виной openjdk версия явы, которая не умеет эти циклические зависимости резолвить.
Начали копать дальше, выяснили что на 5ти стендах у нас 5 разных версий явы от 3х вендоров: ibm java/openjdk/oracle.
С тех пор недоверяю никому вокруг...
Большую часть подобных оплошностей я допускал, как и принято в нормальных кругах, хотфиксами. Ну так бывает, когда сервису плохо, то малоинвазивный фикс, который катится без автотестов и из локальный сборки валит все к херам. Или когда в последнюю секунду загоняешь в состав релиза хотелку бигбоса.
Но в тот раз все было по совести. Кровавый финтех энтерпрайз ставит высокие заборы между тестированием, разработкой, поддержкой приложения и поддержкой инфраструктуры. Зачем это делается? Ну чтоб вы не вошли в преступный сговор и не украли ценные данные (по крайней мере так нам говорили). На практике это скатывается в общение через тикет системы с прикладыванием подорожника и надеждой что инфраструктурные изменения (как и любые другие) будут сделаны по совести.
И так, у нас было 5 тестовых стендов разной степени осознанности, сначала в докерах на заглушках, потом на тестовый стенд, потом staging, preprod -> prod. С автотестами и ручными и демо бизнесу и еще много чем. Котим в прод и все валится к херам.
Смотрим ошибку - приложение не поднимается из-за циклических зависимостей. Ну да, так-то серьезный косяк. А локально и на тестовых стендах все работает. А в проде не работает. Оказалось что всему виной openjdk версия явы, которая не умеет эти циклические зависимости резолвить.
Начали копать дальше, выяснили что на 5ти стендах у нас 5 разных версий явы от 3х вендоров: ibm java/openjdk/oracle.
С тех пор недоверяю никому вокруг...
Сегодня мне лень думать о том как красиво рассказать о bug zero policy и его вариациях, по этому решил протянуть руку помощи фронтендерам.
Если вы, как и я, поднимая голову вокруг осознаете что у вас в package.json хранятся только deprecated и безумно устарелые версии бабела, роута и других библиотек, а переезд на новые версии библиотек не заводится, то это для вас:
updtrJS - модуль который пытается апгрейдить версии библиотек до тех пор пока тесты проходят
А с циклическими зависимостями из прошлого поста во фронте справится madge
Если вы, как и я, поднимая голову вокруг осознаете что у вас в package.json хранятся только deprecated и безумно устарелые версии бабела, роута и других библиотек, а переезд на новые версии библиотек не заводится, то это для вас:
updtrJS - модуль который пытается апгрейдить версии библиотек до тех пор пока тесты проходят
А с циклическими зависимостями из прошлого поста во фронте справится madge
{kind=link}
Почему принцип честности и справедливости не работает?
У всех обиженых и обделенных часто возникает вопрос: почему больше всего работы сделал я, а больше всего денег получает топ-менеджер Миша? Очень часто на этом и заканчиваются рассуждения типичного программиста/тимлида и иже с ним. Проблема в том, что люди оперируют при принятии решения понятиями “справедливо/несправедливо” (кто ваще сказал, что так должно быть?) и оценивают непосредственно объем проделанной “физической” работы, сколько раз я нажамкал на клавиатуру и сколько калорий потратил.
Роберт Сапольски - профессор биологии из Стэнфорда - разжевывает данный пример в рамках исследования внутривидовых стратегий взаимодействия. Исторически считалось, что внутривидовые взаимоотношения построены по принципу “поступай так же, как поступили с тобой”: обидели - обидь в ответ, сделали добро, помоги в след. раз. И этот паттерн реально прослеживался у огромного количества видов, ученые даже почти сошлись на том, что это единственная стратегия взаимодействия животных, а значит вопрос мог быть закрыт и можно было бы заняться более важными вещами. Пока они не начали следить за мадагаскарскими грызунами, внутренний строй которых отличался. Там было 2 типа грызунов:
⁃ Худые и работящие - которые ходят добывать еду и несут ее обратно в нору
⁃ Жирные и ленивые - которые сжирают 80% еды, которую приносят первые
Естественно это грубейшее нарушение баланса привлекло внимание ученых, которые начали более активно следить за животинкой, чтобы понять, что же пошло не так в стройной теории ученых. Ответ нашелся очень быстро, эти грызуны были ночными животными, потому что ночью собирать орехи безопаснее, чем днем. А днем, вот эти вторые, которые ленивые, жрут и ничего не делают, своей жопой закрывают вход в нору, чтобы туда ненароком змея не заползла.
В общем оценивайте риски более мудро, ну и посмотрите его курс “Биология поведения человека”, в свое время мне помогло переосмыслить как все вокруг так происходит.
У всех обиженых и обделенных часто возникает вопрос: почему больше всего работы сделал я, а больше всего денег получает топ-менеджер Миша? Очень часто на этом и заканчиваются рассуждения типичного программиста/тимлида и иже с ним. Проблема в том, что люди оперируют при принятии решения понятиями “справедливо/несправедливо” (кто ваще сказал, что так должно быть?) и оценивают непосредственно объем проделанной “физической” работы, сколько раз я нажамкал на клавиатуру и сколько калорий потратил.
Роберт Сапольски - профессор биологии из Стэнфорда - разжевывает данный пример в рамках исследования внутривидовых стратегий взаимодействия. Исторически считалось, что внутривидовые взаимоотношения построены по принципу “поступай так же, как поступили с тобой”: обидели - обидь в ответ, сделали добро, помоги в след. раз. И этот паттерн реально прослеживался у огромного количества видов, ученые даже почти сошлись на том, что это единственная стратегия взаимодействия животных, а значит вопрос мог быть закрыт и можно было бы заняться более важными вещами. Пока они не начали следить за мадагаскарскими грызунами, внутренний строй которых отличался. Там было 2 типа грызунов:
⁃ Худые и работящие - которые ходят добывать еду и несут ее обратно в нору
⁃ Жирные и ленивые - которые сжирают 80% еды, которую приносят первые
Естественно это грубейшее нарушение баланса привлекло внимание ученых, которые начали более активно следить за животинкой, чтобы понять, что же пошло не так в стройной теории ученых. Ответ нашелся очень быстро, эти грызуны были ночными животными, потому что ночью собирать орехи безопаснее, чем днем. А днем, вот эти вторые, которые ленивые, жрут и ничего не делают, своей жопой закрывают вход в нору, чтобы туда ненароком змея не заползла.
В общем оценивайте риски более мудро, ну и посмотрите его курс “Биология поведения человека”, в свое время мне помогло переосмыслить как все вокруг так происходит.
YouTube
Биология поведения человека: Лекция #3. Эволюция поведения, II [Роберт Сапольски, 2010. Стэнфорд]
Поддержать проект можно по ссылкам:
Если вы в России: https://boosty.to/vertdider
Если вы не в России: https://www.patreon.com/VertDider
Представляем вам третью лекцию курса «Биология поведения человека» профессора Стэнфордского университета Роберта Сапольски.…
Если вы в России: https://boosty.to/vertdider
Если вы не в России: https://www.patreon.com/VertDider
Представляем вам третью лекцию курса «Биология поведения человека» профессора Стэнфордского университета Роберта Сапольски.…
Обожаю чувствовать себя тупым!
На выходные гонял в некультурную. Все как обычно: встретиться с одногруппниками/друзьями, сходить в театр и попить пивка. В очередной раз поразился тому, какие же люди крутые. Валентин занимался/занимается всякими сомнительными мид.терм задачами (средней перспективности) нейронных сетей и иже с ним. Чисто с научной точки зрения.
В свое время он мне рассказал, что занимается Reinforcement Learning, тогда это звучало оч. сомнительно и выглядело как бесполезная магия, а сейчас лаборатория DeepPavlov, в которой он тогда работал, зарелизила поддержку bot-api, которая умеет давать context’ related ответы на вопросы пользователей. Грубо говоря, люди научили машину понимать смысл написаного и давать осмысленные ответы на 6ти языках.
Сейчас он занимается другой магической задачей: Supervised Relation Extraction -> попыткой сформировать граф связей в данных и научиться оценивать адекватность этого графа. Спасибо, что заставляешь мне чувствовать себя тупым, успехов тебе во всем и с днем рождения^^
На выходные гонял в некультурную. Все как обычно: встретиться с одногруппниками/друзьями, сходить в театр и попить пивка. В очередной раз поразился тому, какие же люди крутые. Валентин занимался/занимается всякими сомнительными мид.терм задачами (средней перспективности) нейронных сетей и иже с ним. Чисто с научной точки зрения.
В свое время он мне рассказал, что занимается Reinforcement Learning, тогда это звучало оч. сомнительно и выглядело как бесполезная магия, а сейчас лаборатория DeepPavlov, в которой он тогда работал, зарелизила поддержку bot-api, которая умеет давать context’ related ответы на вопросы пользователей. Грубо говоря, люди научили машину понимать смысл написаного и давать осмысленные ответы на 6ти языках.
Сейчас он занимается другой магической задачей: Supervised Relation Extraction -> попыткой сформировать граф связей в данных и научиться оценивать адекватность этого графа. Спасибо, что заставляешь мне чувствовать себя тупым, успехов тебе во всем и с днем рождения^^
deeppavlov.ai
DeepPavlov: an open source conversational AI framework
DeepPavlov is designed for development of production ready chat-bots and complex conversational systems, research in the area of NLP and, particularly, of dialog systems.
#5 Zero bug policy
Обычно мы стартуем проект, и если появляется Bug -> мы принимаем решение: фиксим/скоро пофиксим/фиксим потом. Хороший подход, но человеческая природа такова, что "скоро фиксим" может тянуться с октября 2016го, а фиксим потом вообще не наступит. Так зачем себя обманывать и что с этим можно делать? Zero bug говорит толсто: мы не будем врать клиенту и говорить, что скоро пофиксим (скоро - понятие растяжимое), фикс будет либо сейчас, либо его сейчас не будет.
Сейчас - это не значит, что мы бросаем все и фиксим баг, сейчас - это в следующую итерацию. А для принятия решения “сейчас/никогда” в команде выделяется роль энтомолога (баговеда), который принимает по всем багам решения. Как правило, это тимлид или продакт, потому что нужно хорошо понимать принципы продукта и valuable things.
Зачем это нужно:
- быть честным с клиентом
- не заниматься диггингом в JIRA берлоге
- не создавать ощущение нависшей глыбы в команде
Какие есть варианты для нерисковых парней?
Ну тут просто, пусть у вас 1000 багов в продакшн, следующий релиз должен содержать внутри не более 999 багов. Не обязательно фиксить новые, важно либо закрывать как won’t fix или зафиксить любые другие баги в таком же количестве. Потому что если не брать баги из беклога, то баги будут Капица.
Обычно мы стартуем проект, и если появляется Bug -> мы принимаем решение: фиксим/скоро пофиксим/фиксим потом. Хороший подход, но человеческая природа такова, что "скоро фиксим" может тянуться с октября 2016го, а фиксим потом вообще не наступит. Так зачем себя обманывать и что с этим можно делать? Zero bug говорит толсто: мы не будем врать клиенту и говорить, что скоро пофиксим (скоро - понятие растяжимое), фикс будет либо сейчас, либо его сейчас не будет.
Сейчас - это не значит, что мы бросаем все и фиксим баг, сейчас - это в следующую итерацию. А для принятия решения “сейчас/никогда” в команде выделяется роль энтомолога (баговеда), который принимает по всем багам решения. Как правило, это тимлид или продакт, потому что нужно хорошо понимать принципы продукта и valuable things.
Зачем это нужно:
- быть честным с клиентом
- не заниматься диггингом в JIRA берлоге
- не создавать ощущение нависшей глыбы в команде
Какие есть варианты для нерисковых парней?
Ну тут просто, пусть у вас 1000 багов в продакшн, следующий релиз должен содержать внутри не более 999 багов. Не обязательно фиксить новые, важно либо закрывать как won’t fix или зафиксить любые другие баги в таком же количестве. Потому что если не брать баги из беклога, то баги будут Капица.
На хайпе!
Сегодня засетапили режим удаленной работы (из-за того кого нельзя называть), т.к. большая часть сотрудников никогда так не работали, то долго и нудно проговаривали правила игры. В конечном итоге сошлись на том, что если ответы на 2 вопроса ниже разные - то демократия по удаленке резко заканчивается и начинается тоталитаризм:
- Просрали ли мы цель спринта?
- Просрали бы мы цель српинта, если бы работали очно?
Не знаю, что из этого выйдет, ибо местами безумно стремно лишаться линейки микроменеджера.
з.ы.
Ну и т.к. на хайпе, то попиарю наш блог и наших китайских партнеров, которые наглядно показывают, как инструменты моделирования помогают принимать решения на agent-based SEIR моделях.
Сегодня засетапили режим удаленной работы (из-за того кого нельзя называть), т.к. большая часть сотрудников никогда так не работали, то долго и нудно проговаривали правила игры. В конечном итоге сошлись на том, что если ответы на 2 вопроса ниже разные - то демократия по удаленке резко заканчивается и начинается тоталитаризм:
- Просрали ли мы цель спринта?
- Просрали бы мы цель српинта, если бы работали очно?
Не знаю, что из этого выйдет, ибо местами безумно стремно лишаться линейки микроменеджера.
з.ы.
Ну и т.к. на хайпе, то попиарю наш блог и наших китайских партнеров, которые наглядно показывают, как инструменты моделирования помогают принимать решения на agent-based SEIR моделях.
Anylogic
Early insight into Coronavirus spread in China
A research paper from the outbreak of COVID-19 in China. Detailing its spread under conditions of control.
Второй день работы из дома.
Начинаю сходить с ума, нет понимания кто и чем занимается. Складывается ощущение, что видео по Zoom мотивирует только меня. Такой формат работы подразумевает много дополнительной работы над асинхронными коммуникациями, которые внутри команды я делать совершенно не умею. Одно дело пнуть подрядчика, поставить дедлайн и заниматься soft push, другое дело сделать тоже самое внутри.
Пришел к выводу, что нужно больше писать друг другу о том, что было сделано и начать хвастаться минидостижениями. Ну и начал читать много всякой фигни про организацию удаленной работы, пока что в топе GitLab
Начинаю сходить с ума, нет понимания кто и чем занимается. Складывается ощущение, что видео по Zoom мотивирует только меня. Такой формат работы подразумевает много дополнительной работы над асинхронными коммуникациями, которые внутри команды я делать совершенно не умею. Одно дело пнуть подрядчика, поставить дедлайн и заниматься soft push, другое дело сделать тоже самое внутри.
Пришел к выводу, что нужно больше писать друг другу о том, что было сделано и начать хвастаться минидостижениями. Ну и начал читать много всякой фигни про организацию удаленной работы, пока что в топе GitLab
The GitLab Handbook
GitLab's Guide to All-Remote
How to work remotely - the GitLab guide
Раньше продукты потипу wix и tilda мне казались не тру бредом. Потому что бедный функционал, странное решение и нет тру инжинера, который засрет твою идею.
Теперь мое мнение другое: nontech and even tech staff может быстро настругать и проверить то что нужно. Рили, делал штук 15 на своей памяти примитивных конструкторов сайтов «чтоб менеджеры отвалили».
Другое круто, что это дёшево и позволяет быть в тренде, а функционал с каждым днес растет. Skyeng вот состряпали гайды для удаленщика человека и удаленщика надзирателя человека, рекомендую:)
Зы
Все чаще этот сайт всплывает в гиппотезах манагеров разной руки
Теперь мое мнение другое: nontech and even tech staff может быстро настругать и проверить то что нужно. Рили, делал штук 15 на своей памяти примитивных конструкторов сайтов «чтоб менеджеры отвалили».
Другое круто, что это дёшево и позволяет быть в тренде, а функционал с каждым днес растет. Skyeng вот состряпали гайды для удаленщика человека и удаленщика надзирателя человека, рекомендую:)
Зы
Все чаще этот сайт всплывает в гиппотезах манагеров разной руки
skyeng.welcome.tilda.ws
Секреты удалённой работы
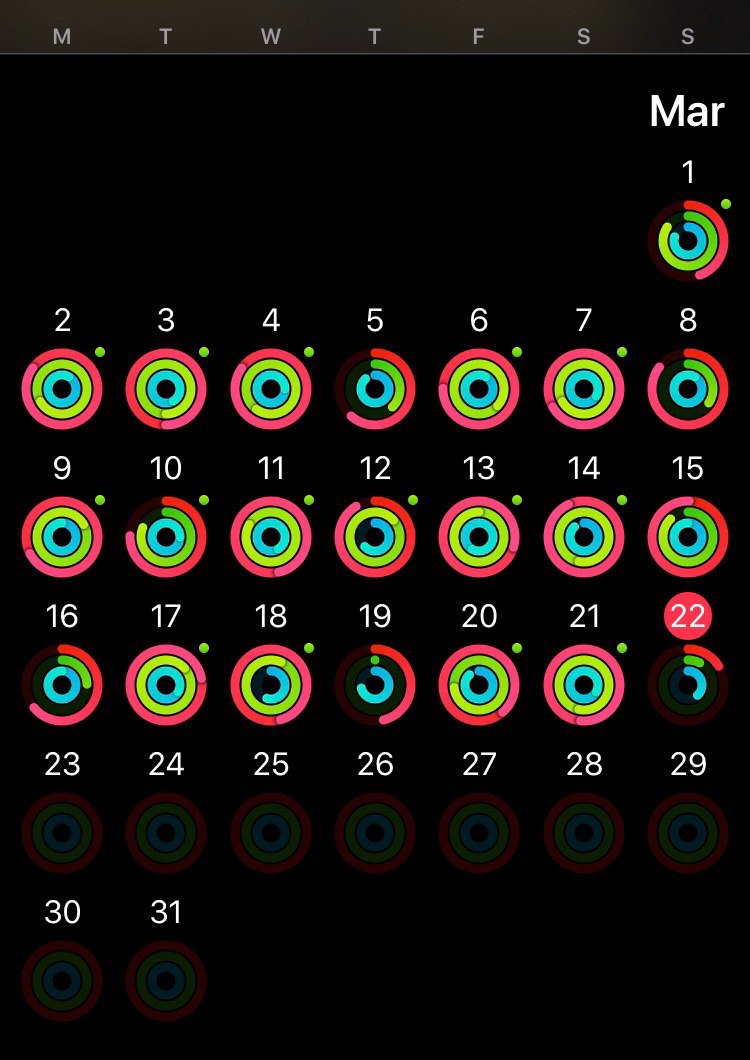
Почему сейчас об этом никто не пишет? Все гайды про то, как организовать удаленку сводятся к тому, как не потерять продуктивность и/или мотивировать свою команду не потерять ее. Про то, как не отсидеть задницу никто не пишет.
Честно говоря я не заметил бы стогнацию, если бы не мои часы. Зеленые точки в углу, это дни, кокгда у меня была тренировка, синий внутренний круг - это “поднимал ли я свой зад в течении часа” - 12 часов активности и ты молодец. Как видно из картинки, рабочая неделя из дома сильно бьет по моему здоровью.
Я честно угорал с людей, которые будучи удаленщиком начинали свой день со спортзала, теперь мне не смешно. Единственное что меня спасло от полного провала - это принудительный график тренировок. Сидячий образ жизни не так вреден, когда ты хотя бы добираешься до работы, но когда выход на работу заключается в том чтобы надеть штаны и сесть за стол - сложно оставаться здоровым.
Думаю буду скоро писать сюда тупые советы, потипу делать стендап в планке.
Честно говоря я не заметил бы стогнацию, если бы не мои часы. Зеленые точки в углу, это дни, кокгда у меня была тренировка, синий внутренний круг - это “поднимал ли я свой зад в течении часа” - 12 часов активности и ты молодец. Как видно из картинки, рабочая неделя из дома сильно бьет по моему здоровью.
Я честно угорал с людей, которые будучи удаленщиком начинали свой день со спортзала, теперь мне не смешно. Единственное что меня спасло от полного провала - это принудительный график тренировок. Сидячий образ жизни не так вреден, когда ты хотя бы добираешься до работы, но когда выход на работу заключается в том чтобы надеть штаны и сесть за стол - сложно оставаться здоровым.
Думаю буду скоро писать сюда тупые советы, потипу делать стендап в планке.
{kind=link}
Сегодня мы напишем с вами на языке java наш первый Service Discovery:
Все готово, можно брать и пользоваться. Теперь осталось понять как подключаться:
Все! Оч сложный язык, правда же?
Ну и чтобы пост был полезным, зачем это нужно, можно почитать тут
@SpringBootApplication
@EnableEurekaServer
public class Eureka {
public static void main(String[] args) {
SpringApplication.run(Eureka.class, args);
}
}
Все готово, можно брать и пользоваться. Теперь осталось понять как подключаться:
@SpringBootApplication
@EnableEurekaClient
public class MyService {
public static void main(String[] args) {
SpringApplication.run(MyService.class, args);
}
}
Все! Оч сложный язык, правда же?
Ну и чтобы пост был полезным, зачем это нужно, можно почитать тут
NGINX
Service Discovery in a Microservices Architecture - NGINX
Explore the service discovery within a microservices architecture, including client-side and server-side discovery patterns, the service registry, & more.
Рубрика, проблемы современных людей
Сделали офер класному разработчику, но, у них весь офис ушел на удаленку (в которую они, как и мы, не особо умеют), теперь сидим и думаем, как ему облегчить выполнение этих двух задач:
- Уволиться с текущего места работы
- Официально трудоустроиться к нам
И смех и грех!
Сделали офер класному разработчику, но, у них весь офис ушел на удаленку (в которую они, как и мы, не особо умеют), теперь сидим и думаем, как ему облегчить выполнение этих двух задач:
- Уволиться с текущего места работы
- Официально трудоустроиться к нам
И смех и грех!
Сейчас учимся оценивать задачи в Story Points. Решил рассказать вам о том, как это происходит на практике:
Когда команда проработает 3-6 месяцев, то смело можно браться за переход на нечто абстрактное. Story Points это подход для тех, кто в силу каких-то причин не может отказаться от среднесрочного планирования, но при этом им не так сильно важна точность. Идей сокрытых в этом подходе довольно много и они на мой взгляд достаточно красивы:
⁃ Идея асимптотической сходимости оценки
⁃ Идея визуализации роста velocity команды
⁃ Идея нормировки задач, а как следствия расчета роста скилов ее участников
В целом это большая попытка поймать “правильный” баланс между временными затратами на оценку задачи и точностью этой оценки.
Как мы это организовали:
1) Выбрали шкалу Фибоначчи (альтернатива - степени двойки): 1/2/3/5/8/13/21 StoryPoints - это все доступные для нас опции оценки задач, других от ныне больше нет.
2) Далее, я выгрузил 100 рандомных задач, которые команда сделала за последние пол года и закинул их на Trello доску.
3) Создал 7 колонок со StoryPoints и колонку с беклогом (список задач)
4) Оглашаем внутренние правила оценок: оценка не должна быть привязана к количеству времени, которое было затрачено на задачу, оценка не должна быть привязана ко времени, за которое я сейчас сделаю эту задачу.
StoryPoint - это такая абстрактная штука, которая показывает количество работы, которую нужно сделать, чтобы задача стала выполненной, что-то наподобие емкости задачи, если можно себя выразить.
5) Как проверить себя на наличие ментальных ловушек: а) если оценка одной и той же задачи (или очень похожих) меняется во времени, значит вы делаете что-то не так б) если вы очень умный и посчитали среднее время выполнения одного сторипоинта - то вы мудак и не поняли основную идею
6) Правила оценки озвучены, у нас есть 100 задач, команда делится на 2 части и начинает таскать задачи из беклога по соответствующим колонкам. Одна команда идет сверху вниз, другая снизу вверх. Важно раскидать все за 10 минут (это примерно 10-12 секунд на одну задачу)
7) После того, как все раскидано, нужно разобраться с каждой колонкой: а) все ли задачи внутри, лежат в правильной колонке (если нет - то дораскидать по правильным колонкам) б) найти “эталонные задачи”, которые характеризуют эту колонку и вытянуть их в топ
8) Теперь у нас есть логарифмическая линейка, просто берем нашу задачу и сравниваем емкость с емкостью эталонной задачи. Среднее время поиска оценки сводится к 30 секундам + обсуждения 2-3 минуты в очень диких кейсах
Обычно, точность определения правильной колонки на первой такой игре будет примерно 60-70% (имхо, многие люди не умеют в такую точность), если проводить игру с некой периодичностью, то эталонные задачи обрастут деталями и пониманием всех участников команды7
Но если вам очень лень думать в эту сторону, вы всегда можете воспользоваться этой шкалой.
Когда команда проработает 3-6 месяцев, то смело можно браться за переход на нечто абстрактное. Story Points это подход для тех, кто в силу каких-то причин не может отказаться от среднесрочного планирования, но при этом им не так сильно важна точность. Идей сокрытых в этом подходе довольно много и они на мой взгляд достаточно красивы:
⁃ Идея асимптотической сходимости оценки
⁃ Идея визуализации роста velocity команды
⁃ Идея нормировки задач, а как следствия расчета роста скилов ее участников
В целом это большая попытка поймать “правильный” баланс между временными затратами на оценку задачи и точностью этой оценки.
Как мы это организовали:
1) Выбрали шкалу Фибоначчи (альтернатива - степени двойки): 1/2/3/5/8/13/21 StoryPoints - это все доступные для нас опции оценки задач, других от ныне больше нет.
2) Далее, я выгрузил 100 рандомных задач, которые команда сделала за последние пол года и закинул их на Trello доску.
3) Создал 7 колонок со StoryPoints и колонку с беклогом (список задач)
4) Оглашаем внутренние правила оценок: оценка не должна быть привязана к количеству времени, которое было затрачено на задачу, оценка не должна быть привязана ко времени, за которое я сейчас сделаю эту задачу.
StoryPoint - это такая абстрактная штука, которая показывает количество работы, которую нужно сделать, чтобы задача стала выполненной, что-то наподобие емкости задачи, если можно себя выразить.
5) Как проверить себя на наличие ментальных ловушек: а) если оценка одной и той же задачи (или очень похожих) меняется во времени, значит вы делаете что-то не так б) если вы очень умный и посчитали среднее время выполнения одного сторипоинта - то вы мудак и не поняли основную идею
6) Правила оценки озвучены, у нас есть 100 задач, команда делится на 2 части и начинает таскать задачи из беклога по соответствующим колонкам. Одна команда идет сверху вниз, другая снизу вверх. Важно раскидать все за 10 минут (это примерно 10-12 секунд на одну задачу)
7) После того, как все раскидано, нужно разобраться с каждой колонкой: а) все ли задачи внутри, лежат в правильной колонке (если нет - то дораскидать по правильным колонкам) б) найти “эталонные задачи”, которые характеризуют эту колонку и вытянуть их в топ
8) Теперь у нас есть логарифмическая линейка, просто берем нашу задачу и сравниваем емкость с емкостью эталонной задачи. Среднее время поиска оценки сводится к 30 секундам + обсуждения 2-3 минуты в очень диких кейсах
Обычно, точность определения правильной колонки на первой такой игре будет примерно 60-70% (имхо, многие люди не умеют в такую точность), если проводить игру с некой периодичностью, то эталонные задачи обрастут деталями и пониманием всех участников команды7
Но если вам очень лень думать в эту сторону, вы всегда можете воспользоваться этой шкалой.
Twitter
Сева или Лас-Вегас
Универсальная таблица оценки задач изян - 1ч изи - 2ч просто - 4ч вроде просто - 6ч норм - 8ч норм так - 12ч хз - 16ч хз как-то - 20ч как-то сложно - 24ч сложно - 30ч очень сложно - 40ч бля - 48ч пиздец - 60ч пиздец какой-то - 80ч вроде изян - 100ч