
👆Иногда есть необходимость получить данные, которые находятся довольно глубоко. Для этого лучше использовать XPath запросы.
#ZennoPoster,#Xpath
#ZennoPoster,#Xpath
👆 Одна из ситуаций, когда при парсинге Json , получили ❗️исключение❗️. Поэтому, как выход, скрипт пытается найти необходимое значение и заменить его самостоятельно.
#ZennoPoster,#Xpath,#Json
#ZennoPoster,#Xpath,#Json
Как и обещал ранее, буду рассматривать некоторые примеры, которые были реализованы мною в этом скрипте (если будет интересна одноразовая услуга по сбору площадок, используя этот скрипт, пишите).
Очень часто при вёрстки макетов сайта, похожая информация находится в в одинаковых тегах(div,tr,td,span и т.д.), которые для удобства отображения находятся в отдельных классах. Для того, чтобы получить всю эту информацию, необходимо это учесть.
Поэтому в данном примере это учту и покажу xPath запрос, который помог справится с этим.
Работаю с программным комплексом ZennoPoster
1. Обращаемся к свойству('ActiveTab') объекта('instance') и передаём полученную информацию в класс('Tab') (более подробнее писал выше).
2. С помощью XPath запроса передаём найденные элементы в класс 'HtmlElementCollection'.
Интересный момент, на который стоит обратить внимание.
а) Тело самого запроса использует логический оператор "или (|)", это позволяет нам собирать информацию с одинаковых тегов, но у которых разное оформление( "class")
3. Основную информацию об элементах получил, дальше необходимо её обрабатывать.
#ZennoPoster, #Xpath
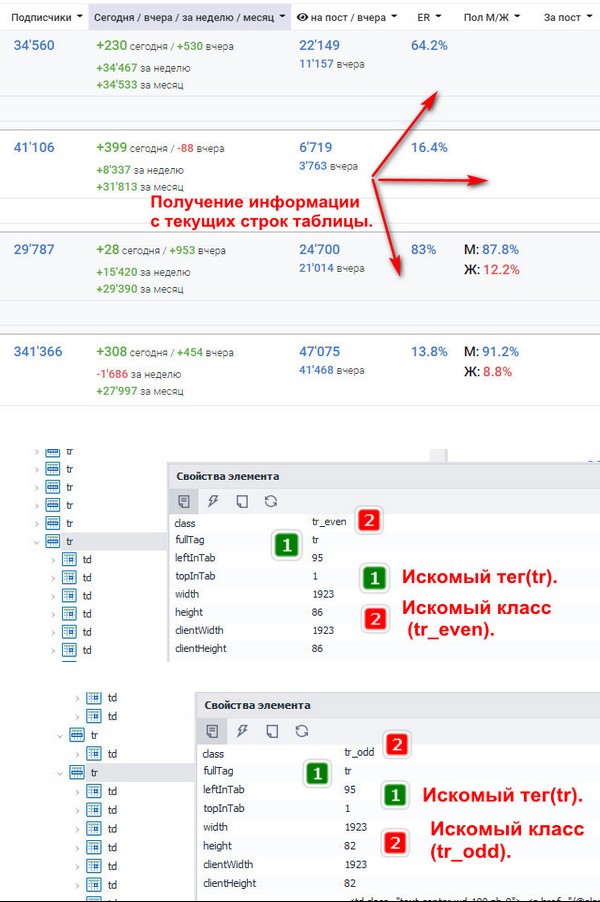
Очень часто при вёрстки макетов сайта, похожая информация находится в в одинаковых тегах(div,tr,td,span и т.д.), которые для удобства отображения находятся в отдельных классах. Для того, чтобы получить всю эту информацию, необходимо это учесть.
Поэтому в данном примере это учту и покажу xPath запрос, который помог справится с этим.
Работаю с программным комплексом ZennoPoster
1. Обращаемся к свойству('ActiveTab') объекта('instance') и передаём полученную информацию в класс('Tab') (более подробнее писал выше).
Tab tab = instance.ActiveTab;2. С помощью XPath запроса передаём найденные элементы в класс 'HtmlElementCollection'.
HtmlElementCollection entries = tab.FindElementsByXPath("//tr[starts-with(@class,'tr_even')] | //tr[starts-with(@class,'tr_odd')]");Интересный момент, на который стоит обратить внимание.
а) Тело самого запроса использует логический оператор "или (|)", это позволяет нам собирать информацию с одинаковых тегов, но у которых разное оформление( "class")
"//tr[starts-with(@class,'tr_even')] | //tr[starts-with(@class,'tr_odd')]"3. Основную информацию об элементах получил, дальше необходимо её обрабатывать.
#ZennoPoster, #Xpath
{kind=link}
Рассматриваю интересные моменты для получения информации используя метод из API Zennoposter: GetChildren.
1. Кол-во блоков с которых необходимо получить информацию из списка.
Итог: Метод
#ZennoPoster, #Xpath
1. Кол-во блоков с которых необходимо получить информацию из списка.
HtmlElementCollection entries = instance.ActiveTab.FindElementsByXPath("//div[contains(@class,'postlist') and contains(@id,'postsList')]/div");
int countBlocks = entries.Count;
2. Получение блоков в которых содержаться две необходимые части(текст и фото).HtmlElement entry = instance.ActiveTab.FindElementByXPath("//div[contains(@class,'postlist') and contains(@id,'postsList')]/div", numRow);
numRow - номер блока для парсинга.HtmlElementCollection entries_m = entry.GetChildren(false);
Рекомендую посмотреть на этот метод: GetChildren(false);
Позволяет получить элементы(детей) от главного элемента(родителя). С ним можно "творить" настоящие чудеса т.к. идёт упрощение кода и нет необходимости писать доп.-ые xpath запросы, чтобы обратиться к нужному элементу.for (p = 0; p < entries_m.Count; p++)
{
HtmlElementCollection entries = entries_m.Elements[p].GetChildren(false);
for (s = 0; s < entries.Count; s++)
{
HtmlElementCollection entries_ = entries.Elements[s].GetChildren(false);
for (m = 0; m < entries_.Count; m++)
{
if (string.IsNullOrEmpty(postTitle))
{
postTitle = entries_.Elements[m].InnerHtml;
project.SendInfoToLog(postTitle);
break;
}
}
}
}
entries_m.Count - полученное кол-во блоков, которое равно 2(т.е. текстовая и фото).HtmlElementCollection entries = entries_m.Elements[p].GetChildren(false);
entries_m.Elements[p].GetChildren(false) - здесь обращаемся к нужному элементу согласно индекса(т.е. 0), из которого также получаем "детей" элемента.Итог: Метод
GetChildren очень мощный метод, который даёт возможность обращаться к нижестоящим элементам без Xpath запросов.#ZennoPoster, #Xpath